构建一个 Human Resource Machine 编译器 - 前言
构建一个 Human Resource Machine 编译器 - 前言
(Thanks to Doubao for translating. See original at this page. 感谢豆包的翻译, 原文见此页面。如有差异,请以英文版为准。如果中文使你困惑看不懂,也请读英文版。)
这是Human Resource Machine 编译器系列的一篇文章。
六年前,当我第一次玩这个关卡的《人力资源机器》游戏时,我突然意识到这个解决方案与编译器通常所做的事情非常相似。从那时起,为《人力资源机器》构建一个编译器的想法就一直萦绕在我的脑海中。
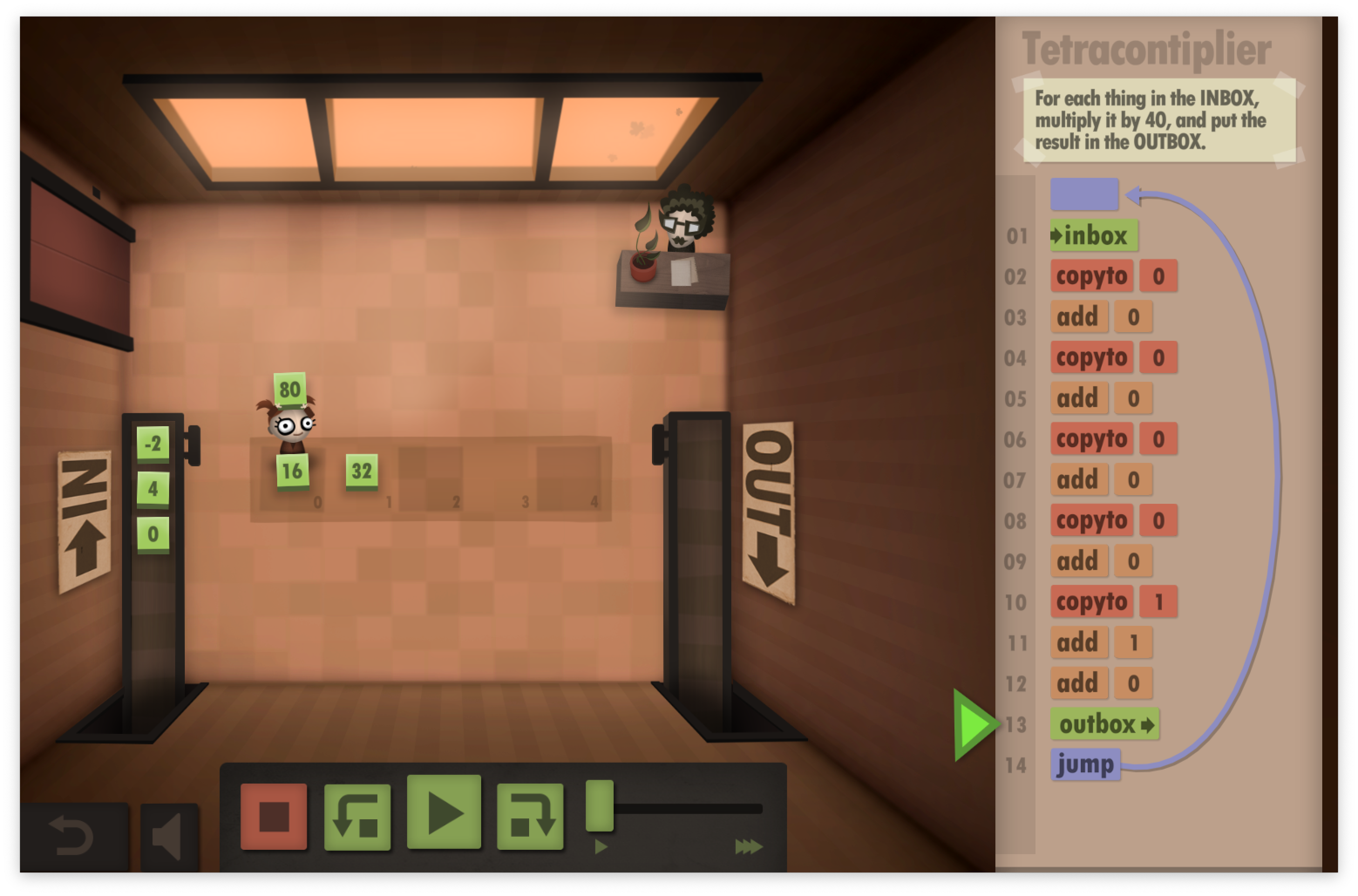
编写汇编代码总是一种令人沮丧的经历(在大多数时候)。这个游戏中的一些关卡需要付出大量的努力才能使指令正确。每次我玩的时候,我都希望有一个编译器能让这个过程更容易。
这么多年后,我终于决定将这个想法变成现实。这个系列将涵盖构建一个不太现代的编译器的过程,从前端到后端,包括语言设计、词法分析、语法分析、中间表示(IR)、代码生成和优化。我们不会涵盖汇编器,因为对于这个游戏来说它是不必要的😊。
最初,我的计划是为 LLVM 实现一个后端,它可以将 IR 编译成 HRM 汇编,允许人们编写一个 C 程序来解决关卡。然而,在花了整个周末在这上面之后,我意识到这种方法几乎是不可能的。《人力资源机器》的架构太简单了,而 LLVM 基于现代架构有很多假设。例如,HRM 绝对没有“函数调用”的能力——它没有栈也没有链接寄存器。一个函数将无法知道它需要返回的调用者地址,除非你手动管理内存地址😣。所以,我们将不得不从头开始构建编译器。
我计划在这个系列中涵盖以下组件。我希望以一种简单易懂的方式解释这些概念,尽管我的知识有些有限。如果这个系列能帮助你解决游戏中的谜题或了解编译器设计,那将是我最大的荣幸。
代码仍在进行中。这个博客上的更新可能会滞后,但我最终会涵盖所有主题。你可以在GitHub上找到代码。请参考这一页获取索引。
- 语言设计
- 词法分析器和语法分析器
- 语义分析器
- 中间表示(IR)生成器
- IR 优化器
- 代码生成器
- 代码优化器